|
Hanchen Cui I am a Ph.D. student in computer science at University of Minnesota Twin Cities, working with Prof. Karthik Desingh. I received my master's and bachelor's degree from Shanghai Jiao Tong University and Xidian University, respectively. Previously, I'm a researcher at Shanghai Qi Zhi Institute, where I work closely with Prof. Yang Gao at IIIS, Tsinghua University. Afterwards, I have a short visit at NUS, collaborating with Prof. Lin Shao My research interest lies in robot learning and my long-term goal is to build a generalized robot that can accomplish long-horizon and complex tasks. To be mroe specific, I work on vision-language-action models, world models, representation learning, and legged locomotion. I am interning at Meta FAIR in the summer of 2025, working on world models and vision-language-action models. Email: hanchen.cui147[at]gmail.com |

|
Publications(representative papers are highlighted) |
|
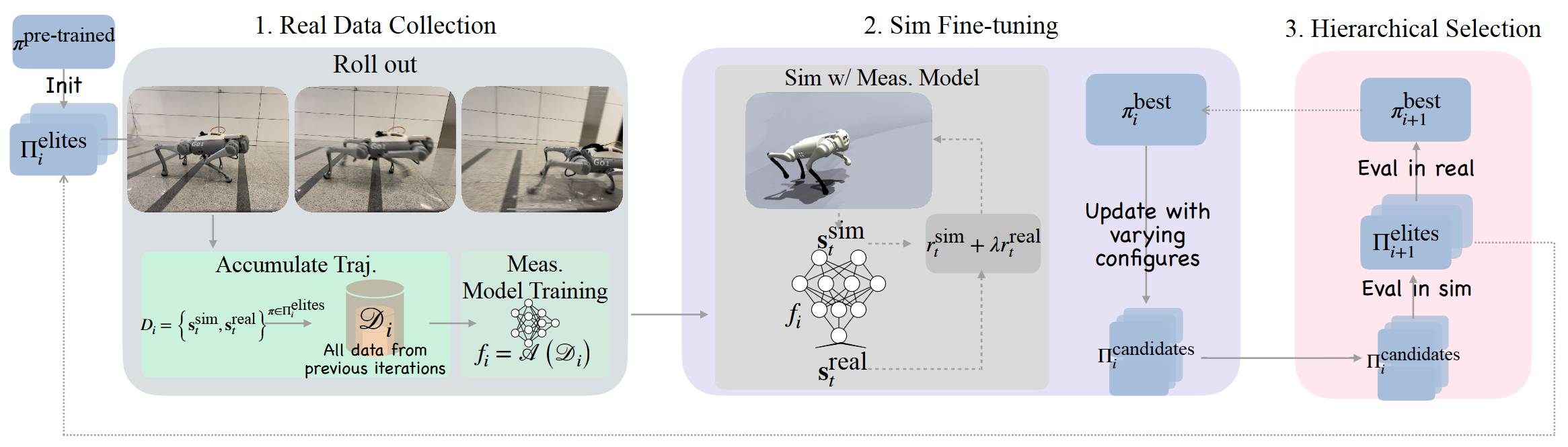
Fine-Tuning Hard-to-Simulate Objectives for Quadruped Locomotion: A Case Study on Total Power Saving
Ruiqian Nai, Jiacheng You, Liu Cao, Hanchen Cui, Shiyuan Zhang, Huazhe Xu, Yang Gao ICRA 2025 project page / pdf We propose a data-driven framework for fine-tuning locomotion policies, targeting these hard-to-simulate objectives. Our framework leverages real-world data to model these objectives and incorporates the learned model into simulation for policy improvement. |
|
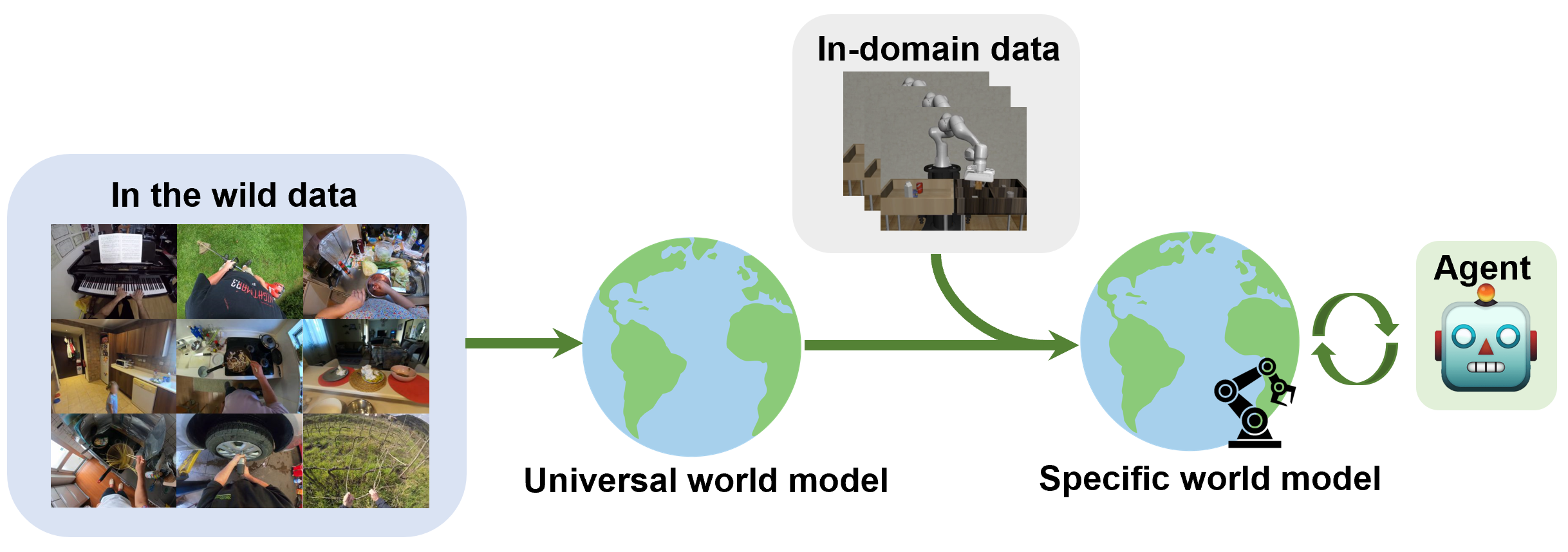
A Universal World Model Learned from Large Scale and Diverse Videos
Hanchen Cui, Yang Gao NeurIPS 2023, Foundation Models for Decision Making Workshop pdf / poster We propose a generalizable world model pre-trained by large scale and diverse video dataset using latent action extracted by VQ-VAE and then fine-tune the world model by robot data to obtain an accurate dynamic function. |
|
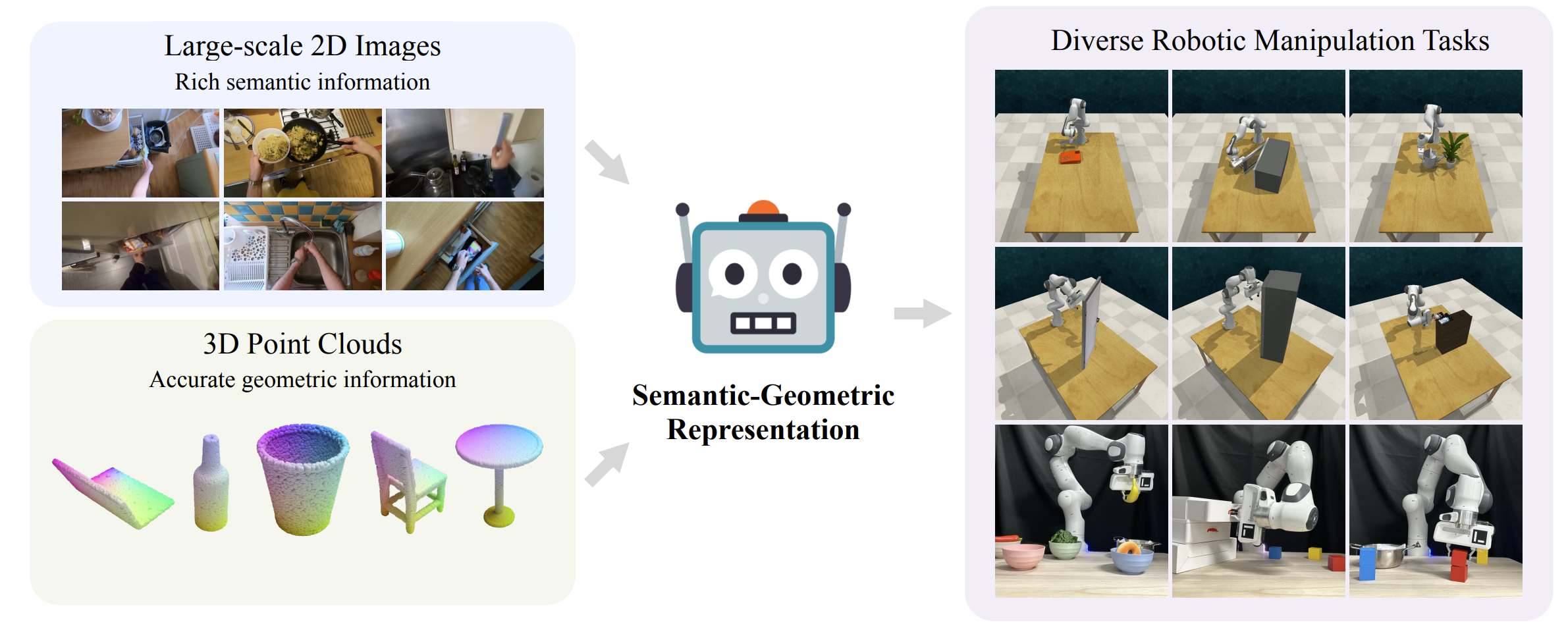
A Universal Semantic-Geometric Representation for Robotic Manipulation
Tong Zhang*, Yingdong Hu*, Hanchen Cui,Hang Zhao, Yang Gao CoRL 2023 project page / arXiv / code We present Semantic-Geometric Representation (SGR), a universal perception module for robotics that leverages the rich semantic information of large-scale pre-trained 2D models and inherits the merits of 3D spatial reasoning. |
Research projects |
|
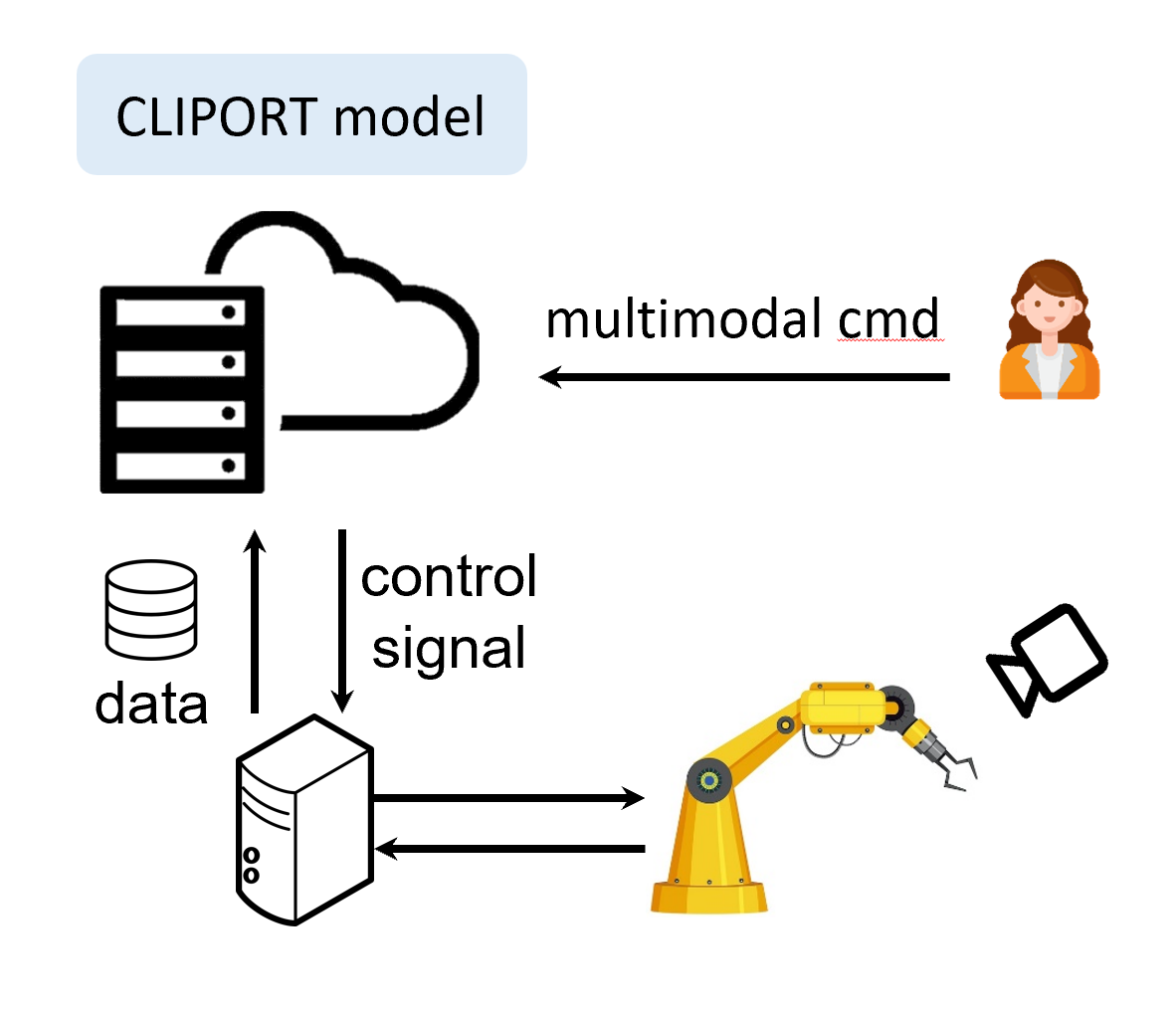
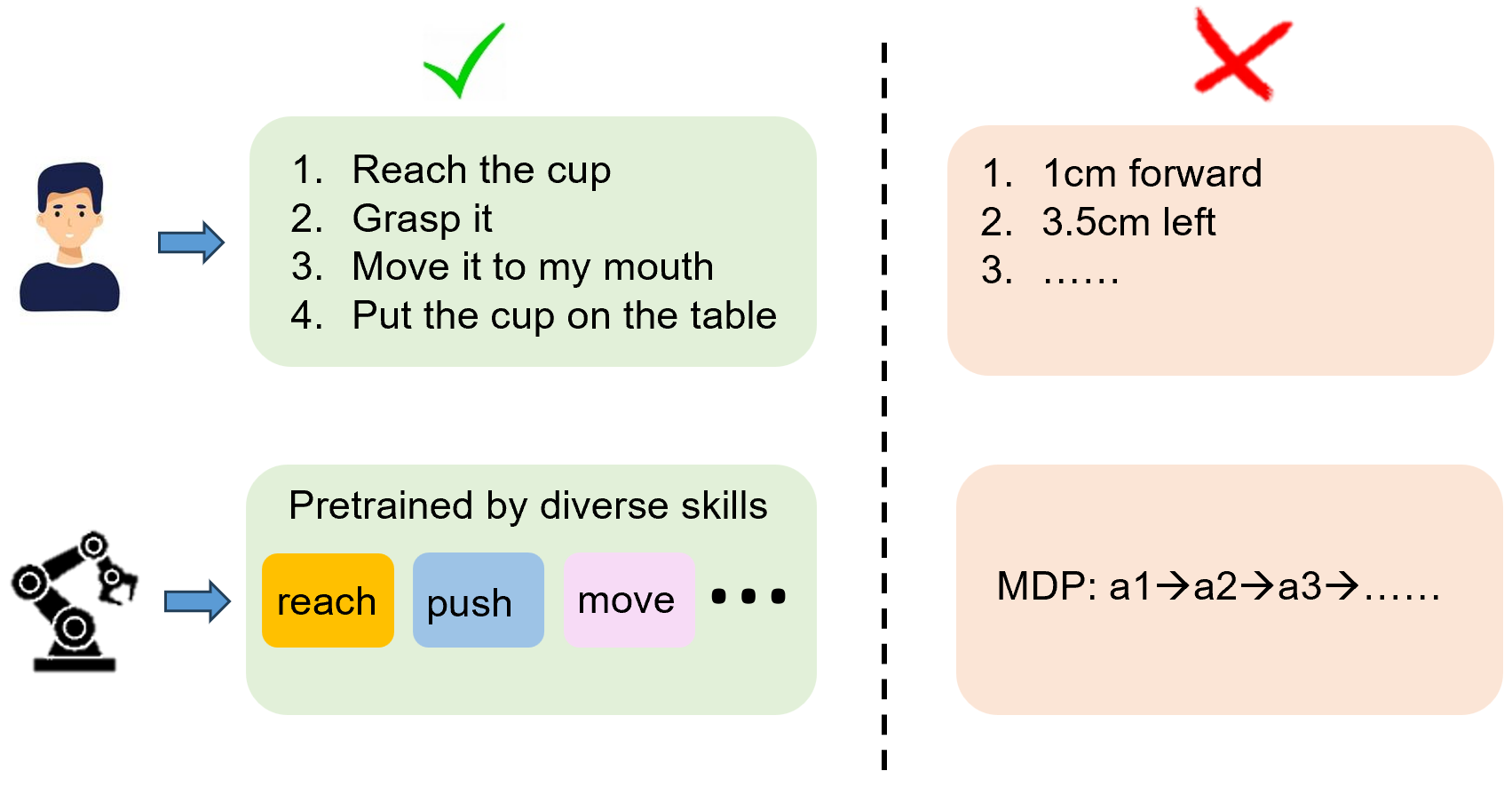
A real-time vision-language manipulation system
(1) Build a vision-language manipulation deployment system to accomplish a variety of real world tasks based on Franka Panda Robot. (2) A robust client-server architecture is employed to enable low-latency remote control. (3) Fine-tune a vision-language manipulation model(CLIPORT), achieving 90% success rate in real-world experiments. |
|
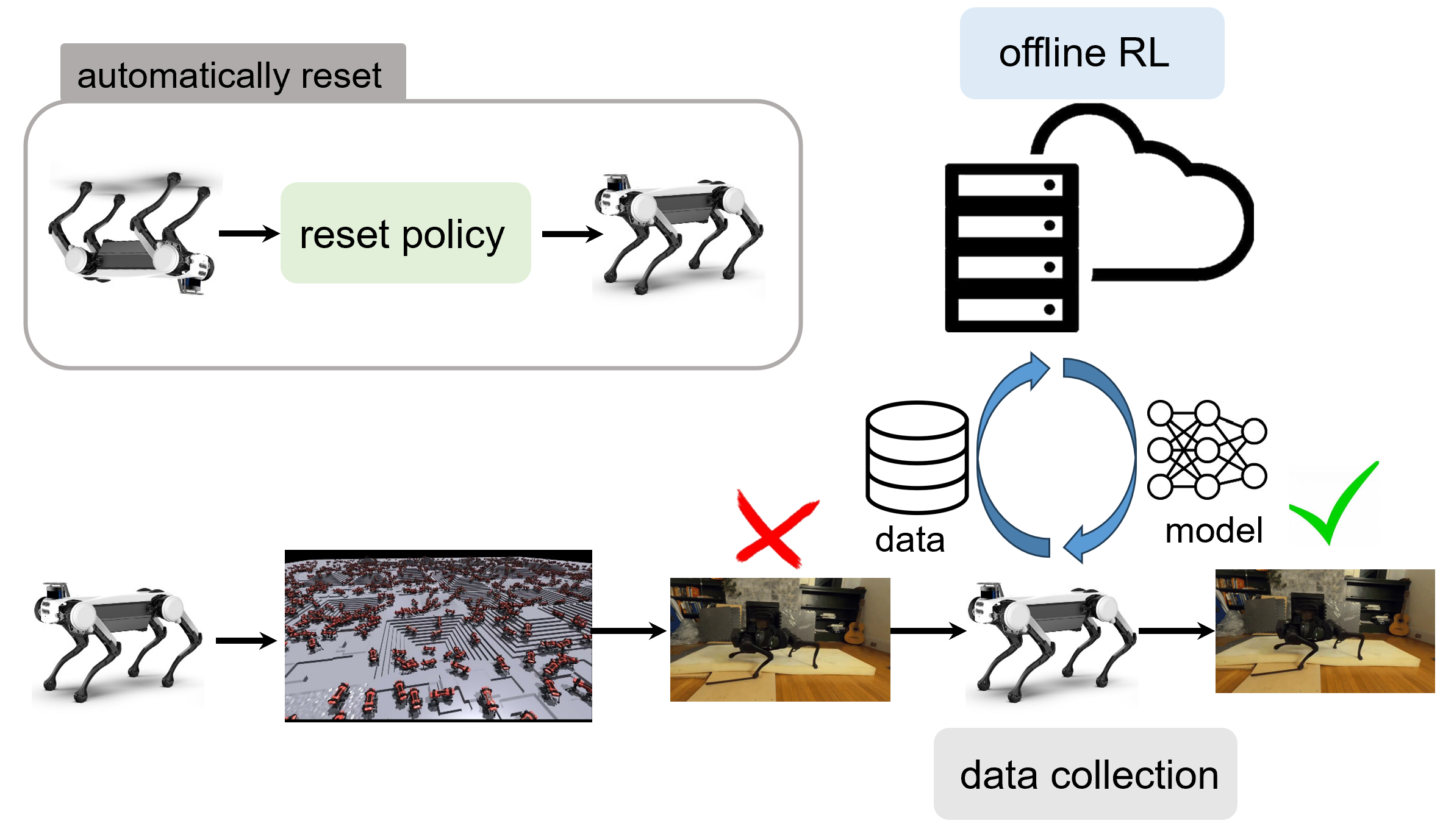
Legged robots learn from physical world
(1) Establish a sim2real locomotion deployment codebase for legged robots. (2) Develop a real-world learning framework that acquires data from real-world interactions and performs policy training on a remote server. |
|
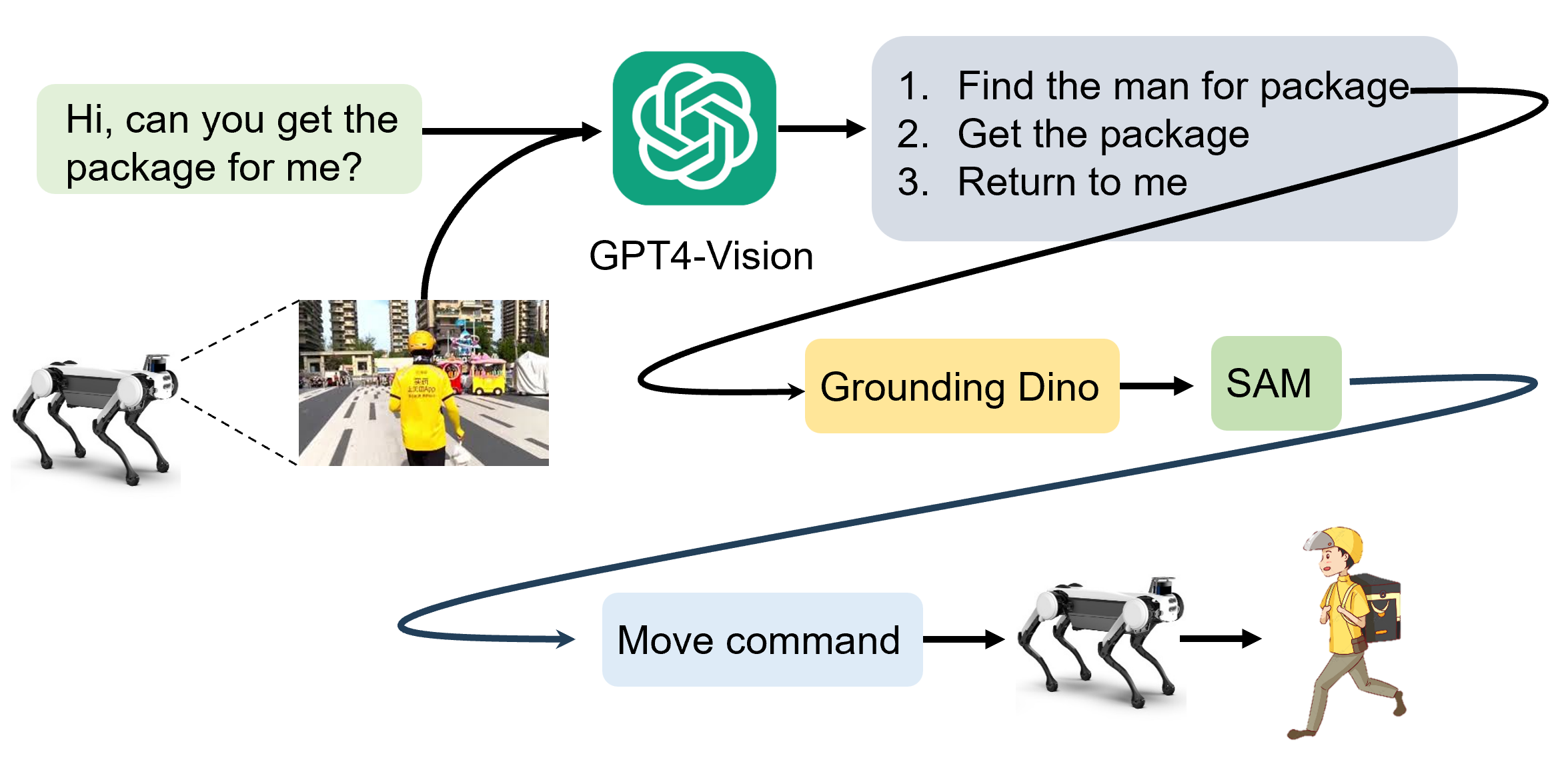
Visual planning for legged robots
(1) Leverage the visual understanding and high-level planning abilities of large multimodal models(like GPT4o), enabling legged robots to accomplish multi-step and complex tasks, such as sending packages, and objects retrieval. |
|
Services
|
|
Modified version of template from here. |